Batch Processing — Hadoop Ecosystem
Let’s review the major components of the Hadoop Ecosystem.
Apache Hadoop Project

The Apache Hadoop project consists of the following key parts:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFSTM): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Latest Hadoop documentation: http://hadoop.apache.org/docs/current/
Distributed FS

The official documentation states: “The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets.”
Key concepts:
- Deployed across multiple servers, called a cluster
- HDFS provides a write-once-read-many access model for files
- Hardware failure is the norm rather than the exception
- Files are spread across multiple nodes, for fault tolerance, HA (high availability), and to enable parallel processing
Architecture

Hadoop follows a master-slave architecture design for data storage and distributed data processing using HDFS and MapReduce respectively:
- The master node for data storage in hadoop HDFS is the NameNode
- The master node for parallel processing of data using Hadoop MapReduce is the Job Tracker
- The slave nodes in the hadoop architecture are the other machines in the Hadoop cluster which store data and perform complex computations
- Every slave node has a Task Tracker daemon and a DataNode that synchronizes the processes with the Job Tracker and NameNode respectively
NameNode & DataNodes
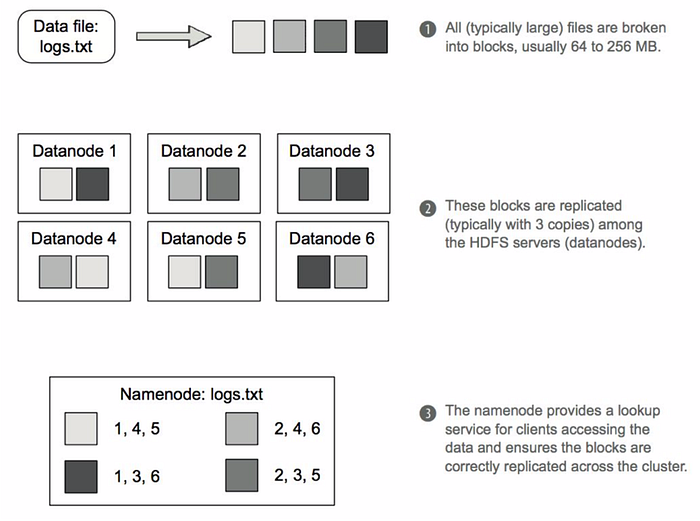
Critical components of HDFS!
- A HDFS cluster consists of a single NameNode (with one or more slave replicas), a master server that manages the file system namespace and regulates access to files by clients
- In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on.
- Basically, application data and metadata are stored separately in HDFS: Master nodes store metadata, and DataNodes store application data
- HDFS exposes a file system namespace and allows user data to be stored in files.
- Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes.
- The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes.
- The DataNodes are responsible for serving read and write requests from the file system’s clients.
- The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
- The NameNode and DataNode communicate with each other using TCP based protocols.
Client Interaction
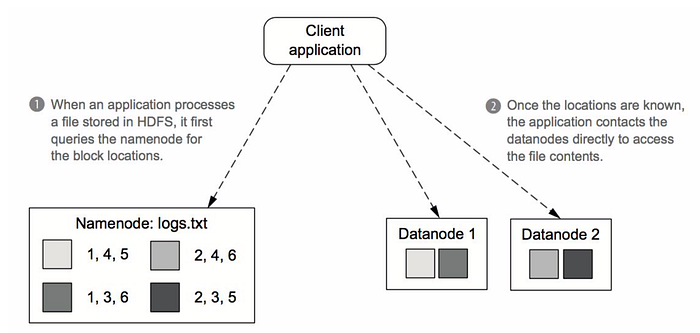
Complexity
You may be wondering why such complexity for something that can be done easily in python on your local computer?
The reasons are:
- Splitting files into blocks enables parallel processing
- Horizontal scalability
- HA (High Availability)
HDFS Setup
- VM
- Managed Service
- Install manually on your own linux server
MapReduce Framework
Typically the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the HDFS are running on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster.
The MapReduce framework consists of:
- A single master ResourceManager
- One slave NodeManager per cluster-node
- MRAppMaster per application.
Minimally, applications specify the input/output locations and supply map and reduce functions via implementations of appropriate interfaces and/or abstract-classes.
These, and other job parameters, comprise the job configuration.
Job Submission
The Hadoop job client then submits the job (jar/executable etc.) and configuration to the ResourceManager which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Hadoop Streaming
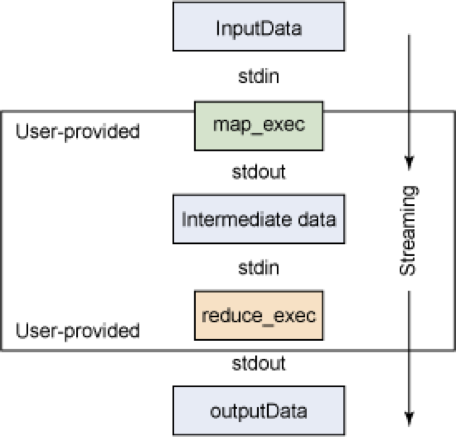
Although the Hadoop framework is implemented in JavaTM, MapReduce applications need not be written in Java — thanks to the Hadoop Streaming
- Hadoop Streaming is a utility which allows users to create and run jobs with any executables (e.g. shell utilities) as the mapper and/or the reducer
- Hadoop Streaming is a generic API which allows writing Mappers and Reduces in any language. But the basic concept remains the same. Mappers and Reducers receive their input and output on stdin and stdout as (key, value) pairs
- Apache Hadoop uses streams as per UNIX standard between your application and Hadoop system — basically , it uses ‘stdin’ and ‘stdout’ streams
- NOT to be confused with Stream Processing — which is a totally different concept of processing real-time data


