Batch Processing — Apache Spark
Let’s talk about batch processing and introduce the Apache Spark framework.
How do you compute Batch Views?
We already know the most important principles and techniques to do processing of large amounts of data:
- Parallelized operations on chunks of data
- Data immutability
- Idempotent operations
- No shared state
And the most important requirements for this kind of processing:
- Fault-tolerance (nodes go down, etc.)
- Horizontal scalability under increasing load
- Zero data loss
- Ability to process all historical data — or a partition of it
We already learned one of the most prevalent techniques to conduct parallel operations on such large scale: Map-Reduce programming model
We also already reviewed a few frameworks that implement this model:
Hadoop MR
Whats next?
Batch Processing
We will consider another example framework that implements the same MapReduce paradigm — Spark
So, what is wrong with HadoopMR and why do we need to look at other frameworks?
While Apache Hadoop has become the most popular open-source framework for large-scale data storing and processing based on the MapReduce model, it has some important limitations:
- Intensive disk-usage
- Low inter-communication capability
- Inadequacy for in-memory computation
- Poor performance for online and iterative computing
Apache Spark
What is Spark?
- Apache Spark is a framework aimed at performing fast distributed computing on Big Data by using in-memory primitives.
- It allows user programs to load data into memory and query it repeatedly, making it a well suited tool for online and iterative processing (especially for ML algorithms)
- It was motivated by the limitations in the MapReduce/Hadoop paradigm which forces to follow a linear dataflow that make an intensive disk-usage.
Spark Platform

When you hear “Apache Spark” it can be two things — the Spark engine aka Spark Core or the Apache Spark open source project which is an “umbrella” term for Spark Core and the accompanying Spark Application Frameworks, i.e. Spark SQL, Spark Streaming, Spark MLlib and Spark GraphX that sit on top of Spark Core and the main data abstraction in Spark called RDD — Resilient Distributed Dataset.
Spark Model

- MapReduce programming model only has two phases: map and/or reduce.
- Complex applications and data flows can be implemented by chaining these phases
- This chaining forms a ‘graph’ of operations — which is known as a “directed acyclic graphs”, or DAGs
- DAGs contain series of actions connected to each other in a workflow
- In the case of MapReduce, the DAG is a series of map and reduce tasks used to implement the application — and it is the developer’s job to define each task and chain them together.
Spark vs Hadoop MR
Main differences between Hadoop MR and Spark:
- With Spark, the engine itself creates those complex chains of steps from the application’s logic. This allows developers to express complex algorithms and data processing pipelines within the same job and allows the framework to optimize the job as a whole, leading to improved performance.
- Memory-based computations
Common features:
- Data locality
- Staged execution (stages separated by shuffle phases)
- Reliance on distributed file system for on-disk persistence (HDFS)
Spark Core
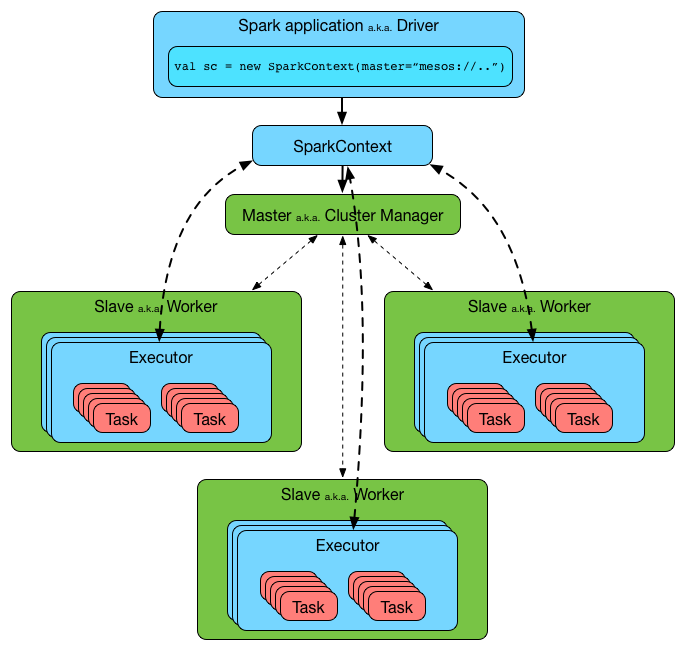
The internal workings are quite complex (read more here).
Similar to Hadoop MR Master-Slave architecture by relying on HDFS for scalable and reliable on-disk persistence
RDD: Resilient Distributed Dataset
- Spark is based on distributed data structures called Resilient Distributed Datasets (RDDs) which can be thought of as immutable parallel data structures
- It can persist intermediate results into memory or disk for re-usability purposes, and customize the partitioning to optimize data placement.
- RDDs are also fault-tolerant by nature. RDD stores information about its parents to optimize execution (via pipelining of operations) and recompute partition in case of failure
- RDD provides API for various transformations and materializations of data
- There are two ways to create RDDs: parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat.
RDDs — Partitions
- RDDs are designed to contain huge amounts of data , that cannot fit onto one single machine → hence, the data has to be partitioned across multiple machines/nodes
- Spark automatically partitions RDDs and distributes the partitions across different nodes
- A partition in spark is an atomic chunk of data stored on a node in the cluster
- Partitions are basic units of parallelism in Apache Spark
- RDDs in Apache Spark are collection of partitions
- Operations on RDDs automatically place tasks into partitions, maintaining the locality of persisted data
RDD — Properties
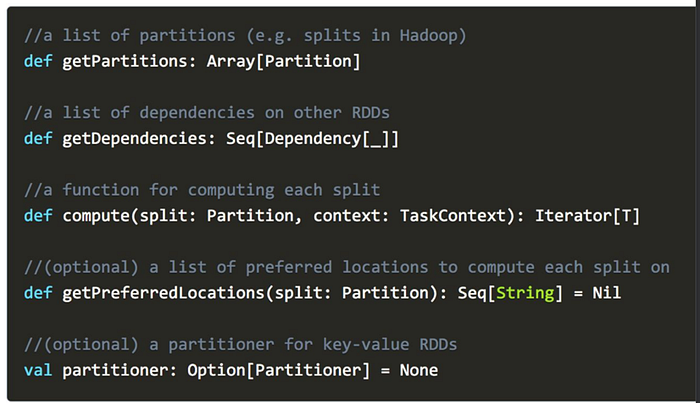
Internally, each RDD is characterized by the following main properties which are defined on the RDD interface:
- a list of partitions
- a list of dependencies on other RDDs
- a function for computing each split
- optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
- optionally, a Partitioner for key-value
RDDs (e.g. to say that the RDD is hash-partitioned)
RDD Creation
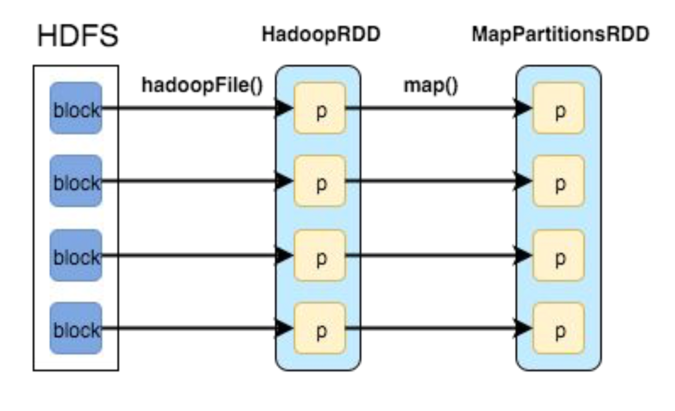
Here’s an example of RDDs created during a method call:
Which first loads HDFS blocks in memory and then applies map() function to filter out keys creating two RDDs:
Spark — Job Architecture
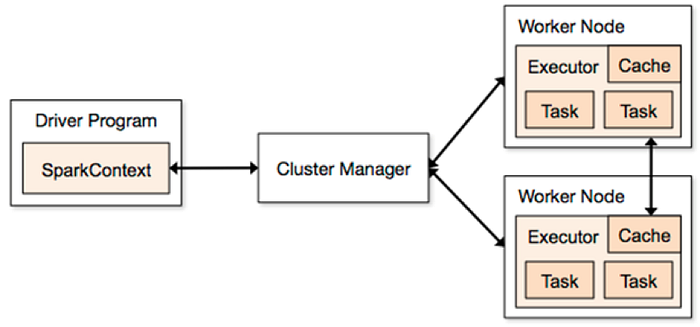
Apache Spark follows a master/slave architecture with two main daemons and a cluster manager –
Master Daemon — (Master/Driver Process)
Worker Daemon — (Slave Process)
A spark cluster has a single Master and any number of Slaves/Workers. The driver and the executors run their individual Java processes and users can run them on the same horizontal spark cluster or on separate machines i.e. in a vertical spark cluster or in mixed machine configuration.
Spark — Driver
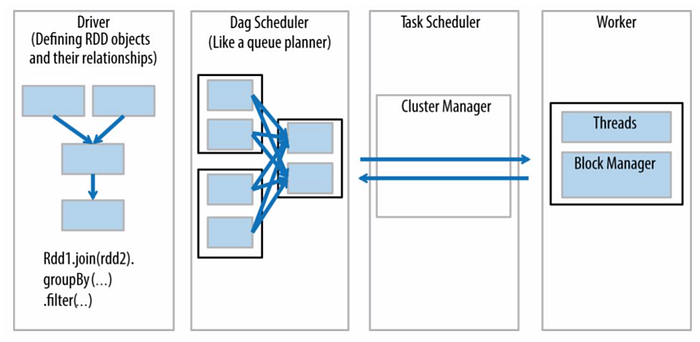
- The Driver is the code that includes the “main” function and defines the RDDs
- Parallel operations on the RDDs are sent to the DAG scheduler, which will optimize the code and arrive at an efficient DAG that represents the data processing steps in the application.
Spark — ClusterManager
- The resulting DAG is sent to the ClusterManager. The cluster manager has information about the workers, assigned threads, and location of data blocks and is responsible for assigning specific processing tasks to workers.
- The cluster manager is also the service that handles DAG play-back in the case of worker failure
Spark — Executor/Workers
Executors/Workers:
- run tasks scheduled by driver
- executes its specific task without knowledge of the entire DAG
- store computation results in memory, on disk or off-heap
- interact with storage systems
- send its results back to the Driver application
Spark — Fault Tolerance
RDDs store their lineage — the set of transformations that was used to create the current state, starting from the first input format that was used to create the RDD.
If the data is lost, Spark will replay the lineage to rebuild the lost RDDs so the job can continue.
Let’s see how this works:
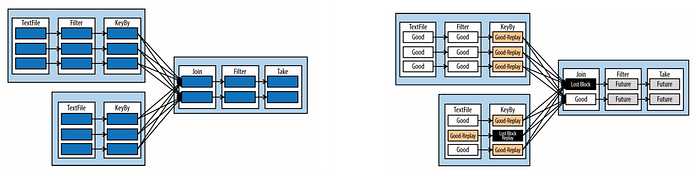
The left image is a common image used to illustrate a DAG in spark. The inner boxes are RDD partitions; the next layer is an RDD and single chained operation.
Take a look at the right image. Now let’s say we lose the partition denoted by the black box. Spark would replay the “Good Replay” boxes and the “Lost Block” boxes to get the data needed to execute the final step
Spark — Execution Workflow
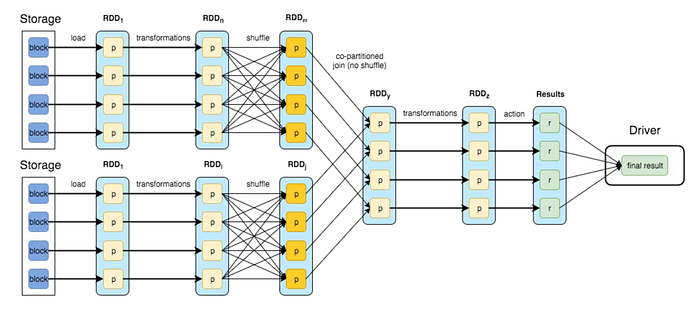
- Client/user defines the RDD transformations and actions for the input data
- DAGScheduler will form the most optimal Direct Acyclic Graph which is then split into stages of tasks.
- Stages combine tasks which don’t require shuffling/repartitioning if the data
- Tasks are then run on workers and results are returned to the client
Lets take a look at how stages are determined by looking at an example of a more complex job’s DAG
Spark — Dependency Types
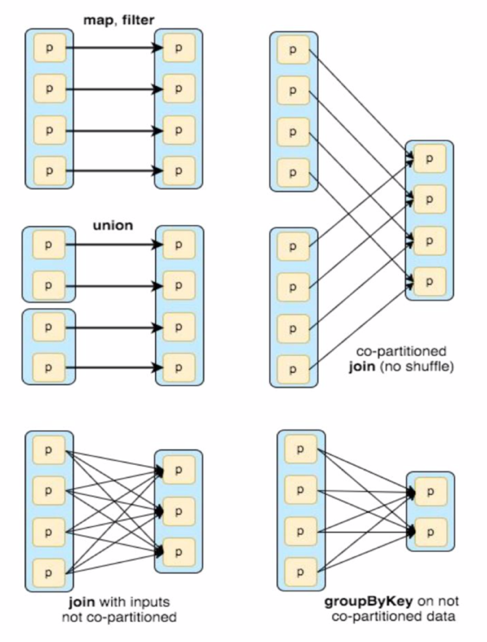
Narrow (pipelineable)
- Each partition of the parent RDD is used by at most one partition of the child RDD
- Allow for pipelined execution on one cluster node
- Failure recovery is more efficient as only lost parent partitions need to be recomputed
Wide (shuffle)
- Multiple child partitions may depend on one parent partition
- Require data from all parent partitions to be available and to be shuffled across the nodes
- If some partition is lost from all the ancestors a complete re-computation is needed
Spark — Stages and Tasks
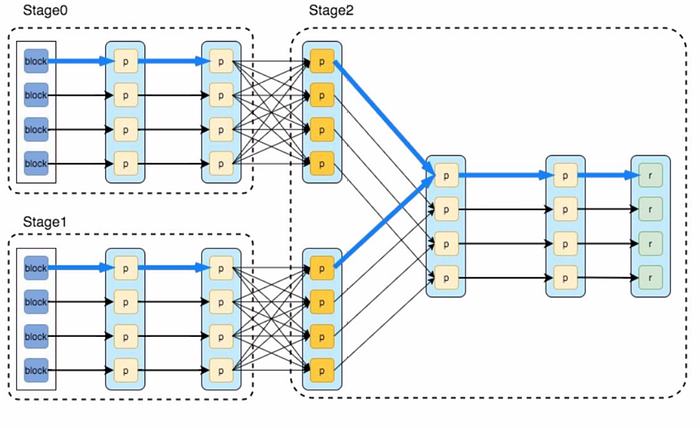
Stages breakdown strategy
- Check backwards from final RDD
- Add each “narrow” dependency to the current stage
- Create new stage when there’s a shuffle dependency
Tasks
- ShuffleMapTask partitions its input for shuffle
- ResultTask sends its output to the driver
Spark — Stages Summary
Summary or the staging strategies:
- RDD operations with “narrow” dependencies, like map() and filter(), are pipelined together into one set of tasks in each stage
- Operations with “wide” /shuffle dependencies require multiple stages (one to write a set of map output files, and another to read those files after a barrier).
- In the end, every stage will have only shuffle dependencies on other stages, and may compute multiple operations inside it
Shared Variables
- Spark includes two types of variables that allow sharing information between the execution nodes: broadcast variables and accumulator variables.
- Broadcast variables are sent to all the remote execution nodes, where they can be used for data processing.
- This is similar to the role that Configuration objects play in MapReduce.
- Accumulators are also sent to the remote execution nodes, but unlike broadcast variables, they can be modified by
the executors, with the limitation that you only add to the accumulator variables. - Accumulators are somewhat similar to MapReduce counters.
SparkContext
- SparkContext is an object that represents the connection to a Spark cluster.
- It is used to create RDDs, broadcast data, and initialize accumulators.
Transformations
- Transformations are functions that take one RDD and return another
- RDDs are immutable, so transformations will never modify their input, only return the modified RDD.
- Transformations in Spark are always lazy, so they don’t compute their results. Instead, calling a transformation function only creates a new RDD with this specific transformation as part of its lineage.
- The complete set of transformations is only executed when an action is called
Most Common Transformations
map() — Applies a function on every element of an RDD to produce a new RDD. This is similar to the way the MapReduce map() method is applied to every element in the input data. For example: lines.map(s=>s.length) takes an RDD of Strings (“lines”) and returns an RDD with the length of the strings.
filter() — Takes a Boolean function as a parameter, executes this function on every element of the RDD, and returns a new RDD containing only the elements for which the function returned true. For example, lines.filter(s=>(s.length>50)) returns an RDD containing only the lines with more than 50 characters.
keyBy() — Takes every element in an RDD and turns it into a key-value pair in a new RDD. For example, lines.keyBy(s=>s.length) return, an RDD of key-value pairs with the length of the line as the key, and the line as the value.
join() — Joins two key-value RDDs by their keys. For example, let’s assume we have two RDDs: lines and more_lines. Each entry in both RDDs contains the line length as the key and the line as the value. lines.join(more_lines) will return for each line length a pair of Strings, one from the lines RDD and one from the more_lines RDD. Each resulting element looks like <length,<line,more_line>>.
groupByKey() — Performs a group-by operation on a RDD by the keys. For example: lines.group ByKey() will return an RDD where each element has a length as the key and a collection of lines with that length as the value
sort() — Performs a sort on an RDD and returns a sorted RDD.
Note that transformations include functions that are similar to those that MapReduce would perform in the map phase, but also some functions, such as groupByKey(), that belong to the reduce phase.
Actions
- Actions are methods that take an RDD, perform a computation, and return the result to the driver application.
- Actions trigger the computation of transformations.
- The result of the computation can be a collection, values printed to the screen, values saved to file, or similar.
- However, an action will never return an RDD.
Example Job
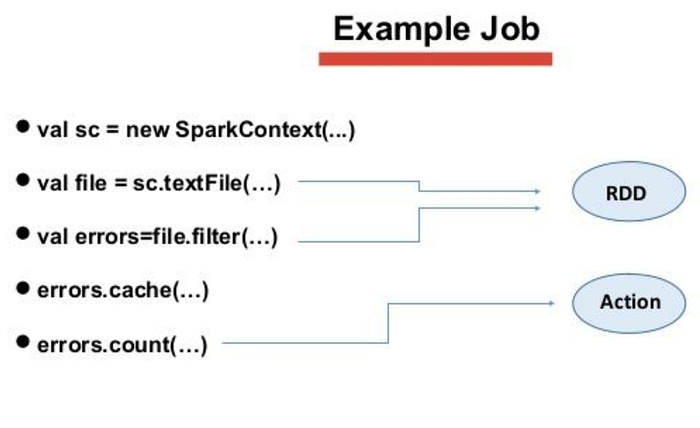
- To start, we initialize a new SparkContext to run commands on our Spark cluster.
- We read in a local log file that we want to process that creates an RDD.
- We put the filter transformation and create a new RDD called errors. We want to check for logs that have error messages.
- The cache commands stores our RDD in memory.
- The count action is the executed. It runs the lazy transformation from before and prints out a value that represents the number of error messages in our log file.
Spark SQL
Spark SQL is all about distributed in-memory computations on structured data on massive scale.
The primary difference between the computation models of Spark SQL and Spark Core is the relational framework for ingesting, querying and persisting (semi)structured data using relational queries that can be expressed using a high-level SQL-like APIs: Dataset API
- Spark SQL’s Dataset API describes a distributed computation that will eventually be converted to a DAG of RDDs for execution.
- Under the covers, structured queries are automatically compiled into corresponding RDD operations.
- Spark SQL supports two “modes” to write structured queries: Dataset API and SQL.
- An older interface: DataFrame — the only option for Python
Spark SQL Example
Here’s a simple example of running spark sql queries on a parquet file. You can check out more examples in the official documentation.

SQL & Parquet
SparkSQL can take direct advantage of the Parquet columnar format in a few important ways:
- Partition pruning: read data only from a list of partitions, based on a filter on the partitioning key, skipping the rest
- Column projection: read the data for columns that the query needs to process and skip the rest of the data
- Predicate push down: is another feature of Spark and Parquet that can improve query performance by reducing the
amount of data read from Parquet files. Predicate push down works by evaluating filtering predicates in the query against metadata stored in the Parquet files. Parquet can optionally store statistics (in particular the minimum and maximum value for a column chunk) in the relevant metadata section of its files and can use that information to take decisions, for example, to skip reading chunks of data if the provided filter predicate value in the query is outside the range of values stored for a given column.
Spark — Job Deployment
Deployment Options:
- Local development and testing — local install and debugging via Eclipse or another IDE
- Cluster installation based on Hadoop
- Cloudera VMs
- AWS EMR with Spark:
Spark — How to Run
Execution Modes
spark-shell — master [ local | spark | yarn-client | mesos]
- launches REPL connected to specified cluster manager
- always runs in client mode
spark-submit — master [ local | spark:// | mesos:// | yarn ] spark-job.jar
- launches assembly jar on the cluster
Masters
- local[k] — run Spark locally with K worker threads
- spark — launches driver app on Spark Standalone installation
- mesos — driver will spawn executors on Mesos cluster (deploy-mode: client | cluster)
- yarn — same idea as with Mesos (deploy-mode: client | cluster)
Deploy Modes
- client — driver executed as a separate process on the machine where it has been launched and spawns executors
- cluster — driver launched as a container using underlying cluster manager
Other Options
Is Spark the only framework that does the in-memory optimizations for MR processing model? No!
There are many…. (too many)
Some flavors are:
- Pure batch/stream processing frameworks that work with data from multiple input sources (Flink, Storm)
- “improved” storage frameworks that also provide MR-type operations on their data (Presto, MongoDB, …)
- Which one is better? The answer, as always, is “it depends”
Wrap-Up
The Apache Spark framework is quite complex and mature. It will take a significant time to understand all the working pieces. We plan on making a separate course dedicated entirely to Spark development in Scala.
Additional Resources
- Spark Core — Check additional reference — http://datastrophic.io/core-concepts-architecture-and-internals-of-apache-spark/
- The best way to learn Spark programming is by following Spark official tutorials: https://spark.apache.org/docs/latest/rdd-programming-guide.html
- Code Examples: https://spark.apache.org/examples.html


